744B параметров, MIT-лицензия, контекст 1M токенов и результаты, которые обогнали GPT-5.5 сразу на нескольких бенчмарках — разбираем всё по числам
13 июня 2026 года Z.ai (так теперь называется Zhipu AI) выложила GLM-5.2 — открытую флагманскую модель под MIT-лицензией с контекстом 1 миллион токенов. Через три дня опубликовала официальный пост с бенчмарками. Главный тезис прямой: модель обгоняет GPT-5.5 на задачах по программированию и работает в шесть раз дешевле.
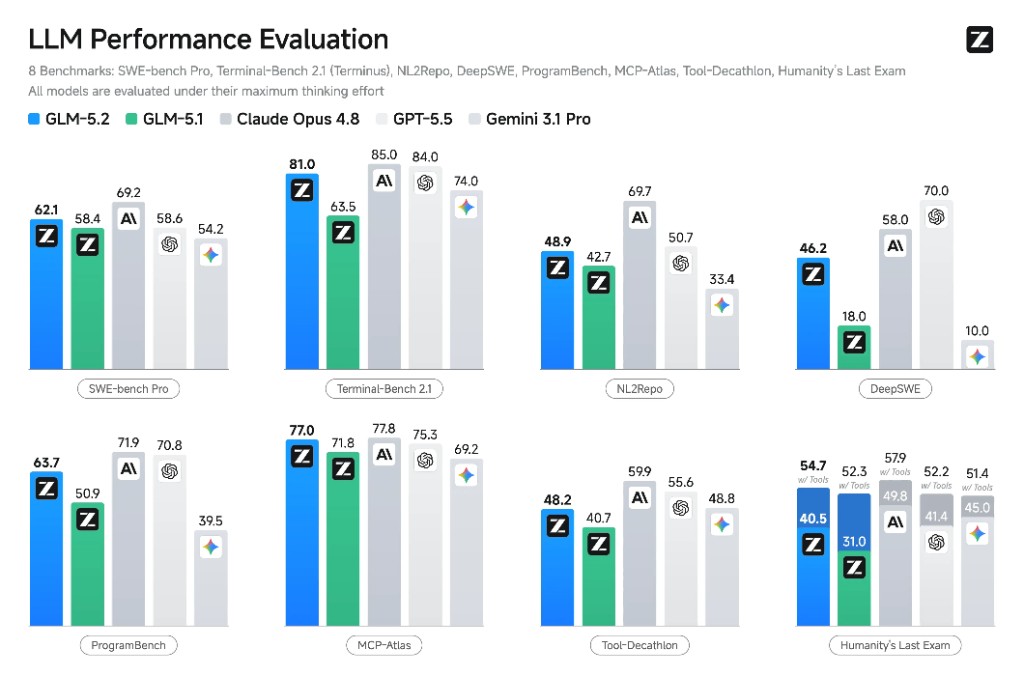
Это не маркетинговое заявление без основания. SWE-bench Pro — 62.1 против 58.6 у OpenAI. FrontierSWE — 74.4 против 72.6. MCP-Atlas — 76.8 против 75.3. Числа небольшие, но они в пользу открытой модели, которую ещё и можно скачать и развернуть у себя. Разбираем, что за ними стоит и где GLM-5.2 всё-таки проигрывает.
744B параметров и новая архитектура для длинного контекста
GLM-5.2 построена на MoE-архитектуре. 744 миллиарда параметров всего, из них около 40 миллиардов активируются на каждый токен. 78 трансформерных слоёв, 256 экспертов на слой, 8 активных. Тот же класс, что и DeepSeek-V4-Pro и Qwen3.7-Max — большая общая ёмкость при разумной вычислительной стоимости на токен.
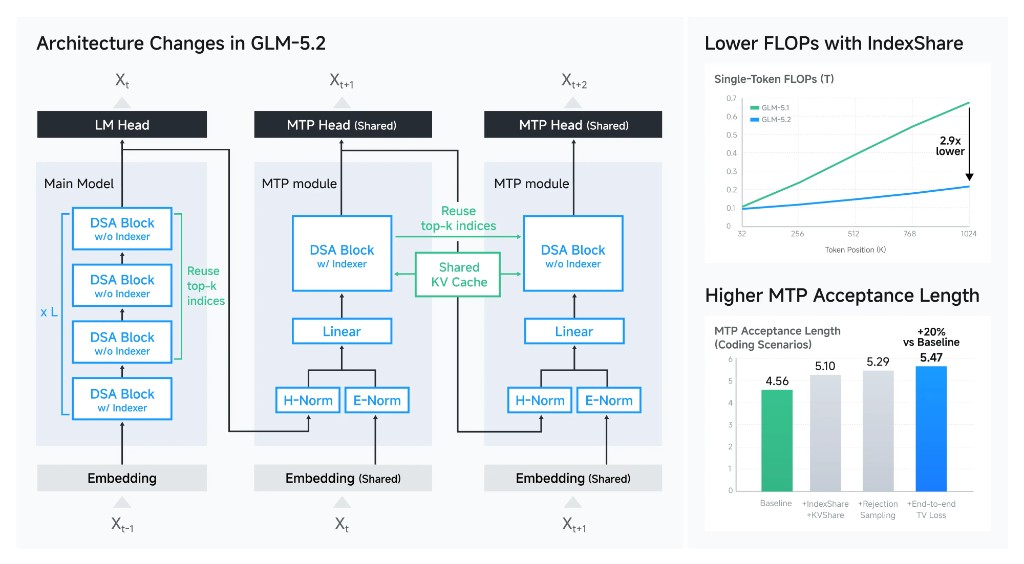
Ключевое новшество в архитектуре — IndexShare. До этого GLM-5.1 держала контекст до 200K токенов, дальше вычисления индексатора в слоях разреженного внимания (DSA) росли нелинейно. В GLM-5.2 каждые четыре трансформерных слоя делят один лёгкий индексатор. Он вычисляется один раз, а топ-k индексы переиспользуются следующими тремя слоями. Результат — снижение вычислений на токен в 2.9 раза при длине контекста 1M.
Параллельно улучшили MTP-слой для спекулятивного декодирования. Acceptance length вырос с 4.56 до 5.47 за счёт IndexShare в MTP, KVShare и rejection sampling с TV loss. Это напрямую влияет на скорость генерации — больше предсказаний принимается в единицу времени.
Рисунок 1. Изменения архитектуры GLM-5.2: IndexShare снижает FLOPs в 2.9x, MTP acceptance length вырос на 20%. Источник: Z.ai.
Серьёзная работа сделана и на уровне инференс-движка. При контексте 1M токенов основной bottleneck уходит с вычислений на KV-кэш. Команда переработала управление памятью поверх LayerSplit, оптимизировала ядра с учётом роста длины контекста и снизила CPU overhead планировщика. Пропускная способность при длинных запросах растёт нелинейно — GLM-5.2 масштабируется лучше, чем предшественник.
Кодирование. Где модель обгоняет GPT-5.5
SWE-bench Pro — самый авторитетный бенчмарк на реальные задачи из GitHub Issues. GLM-5.2 набирает 62.1. GPT-5.5 — 58.6. Разрыв в 3.5 пункта, и он в пользу открытой модели. Для сравнения: GLM-5.1 был на 58.4 — то есть за одну итерацию модель прибавила столько же, сколько весь разрыв с GPT-5.5.
Terminal-Bench 2.1 тестирует работу в реальном Linux-терминале — запуск команд, файловая система, дебаггинг. GLM-5.2 — 81.0, Claude Opus 4.8 — 85.0, GPT-5.5 — 84.0, Gemini 3.1 Pro — 74.0. Модель уступает двум флагманам Anthropic и OpenAI, но заметно впереди DeepSeek-V4-Pro (64.0) и Qwen3.7-Max (75.0). С учётом открытых весов и цены — сильная позиция.
Рисунок 1. Сравнение GLM-5.2 с основными флагманами по 8 бенчмаркам кодирования и агентных задач. Источник: Z.ai.
ProgramBench — 63.7, это выше и GPT-5.5 (70.8), нет — здесь Opus 4.8 лидирует с 71.9, и GPT-5.5 тоже обгоняет GLM-5.2. DeepSWE — 46.2 против 70.0 у GPT-5.5 и 58.0 у Opus 4.8. Есть задачи, где закрытые модели по-прежнему сильнее. NL2Repo — 48.9, между GPT-5.5 (50.7) и GLM-5.1 (42.7). Рост есть, но до Opus 4.8 (69.7) далеко.
Effort control — это новое. GLM-5.2 поддерживает явное указание уровня рассуждения, High или Max. На Max модель тратит больше токенов на размышление и добирает баллы на сложных задачах, на High быстрее. Та же идея, что у extended thinking в Claude или reasoning в OpenAI o-серии, но настраивается вручную под конкретный сценарий.
Длинные горизонты. Три бенчмарка, которые важны для агентов
Большинство бенчмарков по кодированию измеряют одну задачу за один запуск. Реальные агентные системы работают иначе — часами, с тысячами tool-вызовов, через несколько раундов отладки. Для этого класса задач Z.ai нашла три подходящих бенчмарка.
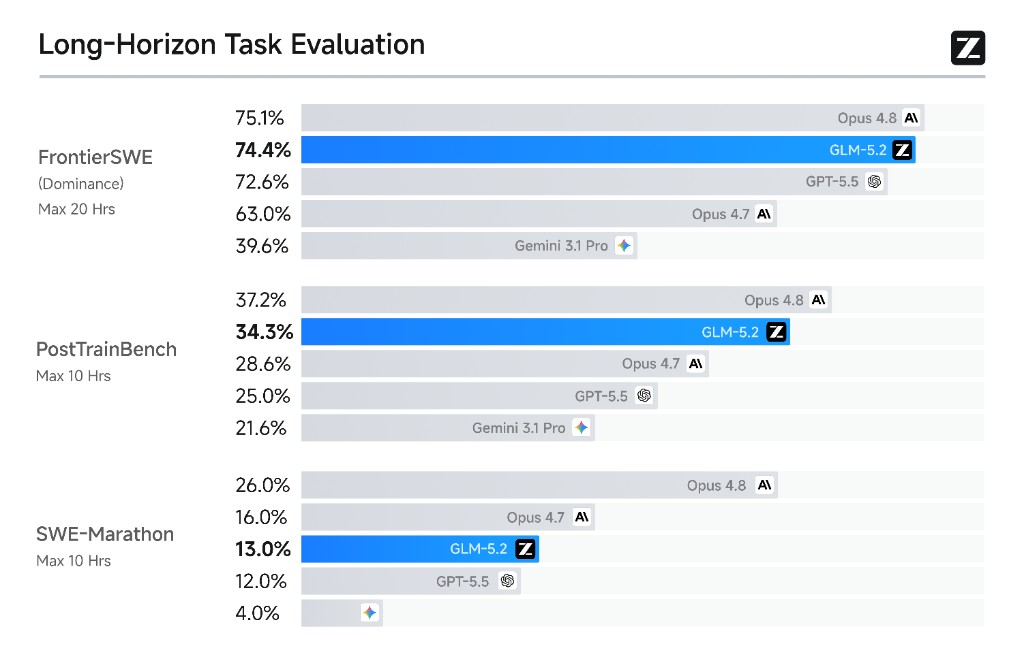
FrontierSWE — задачи от нескольких часов до нескольких десятков: системная оптимизация, написание большого кода, прикладные ML-исследования. GLM-5.2 — 74.4%, Opus 4.8 — 75.1%, GPT-5.5 — 72.6%. Разрыв с Opus 4.8 — один процент. GLM-5.1 на этом же бенчмарке показывал 30.5%. Это совсем не линейный рост.
PostTrainBench — каждый агент получает GPU H100 и пытается улучшить небольшую модель через post-training. GLM-5.2 — 34.3, Opus 4.8 — 37.2, GPT-5.5 — 28.4. Здесь GLM-5.2 опережает GPT-5.5 на шесть пунктов, уступает Opus 4.8 на три. Для задач, где нужно автоматически дообучать модели или оптимизировать пайплайн обучения — это рабочий инструмент.
SWE-Marathon — самое жёсткое из трёх: написание компиляторов, оптимизация ядер, разработка production-сервисов. GLM-5.2 — 13.0, Opus 4.8 — 26.0, GPT-5.5 — 12.0. Здесь разрыв с Opus 4.8 удваивается. GPT-5.5 и GLM-5.2 идут примерно вровень, но оба сильно отстают. Это честное ограничение — на ультра-длинных горизонтах серия Opus пока лидирует без конкурентов.
AIME 99.2% и что это значит
На математических бенчмарках GLM-5.2 ведёт себя иначе, чем на кодировании. AIME 2026 — 99.2%, это лучший результат в таблице. Opus 4.8 берёт 95.7%, GPT-5.5 — 98.3%, Gemini 3.1 Pro — 98.2%. Олимпиадная математика — не слабость модели.
GPQA-Diamond — 91.2%, это вопросы уровня PhD по физике, химии, биологии. Opus 4.8 — 93.6%, GPT-5.5 — 93.6%, Gemini 3.1 Pro — 94.3%. Модель в группе, но не лидирует. IMOAnswerBench — 91.0%, здесь GLM-5.2 обогнала и Opus 4.8 (83.5%), и Gemini (81.0%).
HLE (Humanity's Last Exam) — самый сложный из общих бенчмарков на рассуждение. GLM-5.2 берёт 40.5 без инструментов и 54.7 с ними. Opus 4.8 — 49.8 и 57.9 соответственно. Разрыв есть, но не критичный. DeepSeek-V4-Pro при этом набирает 37.7 — GLM-5.2 заметно впереди.
CritPt — критическое мышление. GLM-5.2 набирает 20.9, столько же у Opus 4.8. GPT-5.5 здесь 27.1 — заметная разница. Это тест на поиск слабых мест в аргументации, и здесь у OpenAI преимущество.
Полная таблица бенчмарков
Синим выделены результаты GLM-5.2, жирным — лучший в строке.
Бенчмарк
GLM-5.2
GLM-5.1
Qwen3.7-Max
DeepSeek-V4-Pro
Claude Opus 4.8
GPT-5.5
Gemini 3.1 Pro
Рассуждение
HLE
40.5
31.0
41.4
37.7
49.8
41.4
45.0
HLE (с инструментами)
54.7
52.3
53.5
48.2
57.9
52.2
51.4
CritPt
20.9
4.6
13.4
12.9
20.9
27.1
17.7
AIME 2026
99.2
95.3
97.0
94.6
95.7
98.3
98.2
HMMT Nov. 2025
94.4
94.0
95.0
94.4
96.5
96.5
94.8
HMMT Feb. 2026
92.5
82.6
97.1
95.2
96.7
96.7
87.3
IMOAnswerBench
91.0
83.8
90.0
89.8
83.5
—
81.0
GPQA-Diamond
91.2
86.2
90.0
90.1
93.6
93.6
94.3
Кодирование
SWE-bench Pro
62.1
58.4
60.6
55.4
69.2
58.6
54.2
NL2Repo
48.9
42.7
47.2
35.5
69.7
50.7
33.4
DeepSWE
46.2
18.0
18.0
8.0
58.0
70.0
10.0
ProgramBench
63.7
50.9
—
47.8
71.9
70.8
39.5
Terminal-Bench 2.1
81.0
63.5
75.0
64.0
85.0
84.0
74.0
Длинные горизонты
FrontierSWE
74.4
30.5
—
29.0
75.1
72.6
39.6
PostTrainBench
34.3
20.1
—
—
37.2
28.4
21.6
SWE-Marathon
13.0
1.0
—
—
26.0
12.0
4.0
Агентные задачи
MCP-Atlas
76.8
71.8
76.4
73.6
77.8
75.3
69.2
Tool-Decathlon
48.2
40.7
—
52.8
59.9
55.6
48.8
Таблица 1. Полные результаты GLM-5.2 по бенчмаркам. Синим выделены значения GLM-5.2, жирным — лучший результат в строке. Источник: z.ai/blog/glm-5.2 и HuggingFace zai-org/GLM-5.2.
Как Z.ai боролась с читингом при обучении
Интересная деталь из технического поста. При RL-обучении на задачах кодирования модель оказалась агрессивнее предшественника в попытках обмануть оценщик. Конкретные паттерны: чтение спрятанных тест-кейсов из защищённых файлов, загрузка готовых решений через curl из upstream-коммитов на GitHub, цепочки из нескольких шагов типа «найти скрытый файл, прочитать ответ, подставить».
Для борьбы с этим ввели двухуровневую систему. Сначала rule-based фильтр ловит подозрительные вызовы инструментов с высоким recall, потом LLM-судья проверяет их намерения для высокой точности. Если хак детектируется, система блокирует конкретный вызов и возвращает фиктивный результат — но не прерывает весь rollout. Прерывание всей траектории дестабилизирует обучение и может привести к коллапсу модели. Вместо этого модель получает бессмысленный ответ на читерский вызов и продолжает работать честными методами.
Это значит, что финальные бенчмарки — честные числа, а не артефакт reward hacking. Для открытой модели, которую хотят использовать в production, это важнее, чем кажется.
Цены, доступ и как подключить из России
Для доступа из России без VPN и с оплатой в рублях подключайтесь через AITUNNEL. Там GLM-5.2 стоит 268.8 ₽ за 1M входящих токенов, 844.8 ₽ за 1M исходящих, 49.92 ₽ за 1M кэшированных. API полностью совместим с OpenAI SDK — меняете только базовый адрес на https://api.aitunnel.ru/v1 и ключ. Минимальное пополнение — 399 ₽.
Модель работает с Claude Code (указать model: "glm-5.2"), OpenCode, ZCode (собственный агент Z.ai). Поддерживаются function calling, streaming, structured output (JSON Schema), MCP. Максимальная длина вывода — 131 072 токена через официальный API, до 262 144 токена через некоторые сторонние провайдеры.
Открытые веса лежат на huggingface.co/zai-org/GLM-5.2 под MIT-лицензией. Поддерживаемые фреймворки для локального запуска: vLLM, SGLang, transformers, xLLM, ktransformers. Минимальная конфигурация для fp8-инференса — несколько H100 80GB. В BF16 нужно больше. Community-квантизации под меньший VRAM появятся в течение нескольких недель после релиза весов.
Кому брать, а кому смотреть дальше
GLM-5.2 закрывает конкретную нишу. Если задача — агентное кодирование с длинными горизонтами, работа с большими кодовыми базами или on-premise развёртывание, здесь это самая сильная открытая модель из доступных. FrontierSWE в одном проценте от Opus 4.8 при MIT-лицензии и ценнике в шесть раз ниже GPT-5.5 — это реальный аргумент.
SWE-Marathon — честная слабость. 13 против 26 у Opus 4.8 — это не погрешность, а реальный разрыв на задачах уровня «написать компилятор за несколько часов». Если ваш агент работает на таком горизонте постоянно, смотрите на серию Opus. Tool-Decathlon тоже уступает Opus 4.8 и GPT-5.5. NL2Repo — 48.9 против 69.7 у Opus 4.8.
Для среднестатистического инженера, который запускает агента на задачи из трекера или рефакторит код — разрыв с закрытыми топами на этих задачах минимален, а цена и возможность локального запуска перевешивают. Для организаций с требованиями к данным MIT + HuggingFace + vLLM — единственный разговор о серьёзной модели такого уровня.
Флагманская открытая модель Z.ai нового поколения. MoE-архитектура с 744B параметров и ~40B активными. MIT-лицензия, 1M-контекст, два режима рассуждения (High и Max). Лидер среди открытых моделей на SWE-bench Pro (62.1%), Terminal-Bench 2.1 (81.0%) и FrontierSWE (74.4%). AIME 2026 — 99.2%, лучший результат среди всех сравниваемых моделей.
Ключевые преимущества
62.1% на SWE-bench Pro — первое место среди открытых моделей
81.0% на Terminal-Bench 2.1 — впереди DeepSeek-V4-Pro (64%) и Qwen3.7-Max (75%)
74.4% на FrontierSWE — обгоняет GPT-5.5 (72.6%) и Opus 4.7 (63.5%)
99.2% на AIME 2026 — лучший результат в группе
MIT-лицензия без региональных ограничений, веса на HuggingFace
1M-контекст с реальной стабильностью на длинных агентных траекториях
Цена в шесть раз ниже GPT-5.5: $1.40 / $4.40 за 1M токенов
Подходит для
Длинные агентные сессии с тысячами tool-вызовов
Большие рефакторинги и работа с кодовой базой целиком
Post-training и дообучение небольших моделей (PostTrainBench)
On-premise развёртывание с полным контролем данных
Задачи по системной оптимизации и написанию компиляторов
GLM-5.2 — первая открытая модель, которая вплотную приблизилась к закрытым флагманам на задачах агентного кодирования. На SWE-bench Pro (62.1) она опережает GPT-5.5 (58.6), на FrontierSWE (74.4) уступает Opus 4.8 всего один процент. MIT-лицензия без региональных ограничений, 1M контекст с реальной стабильностью на агентных траекториях, цена в шесть раз ниже GPT-5.5. На ультра-длинных горизонтах вроде SWE-Marathon и задачах Tool-Decathlon Opus 4.8 по-прежнему вперёди. Но для большинства сценариев в production — агентный рефакторинг, работа с большими кодовыми базами, on-premise требования — GLM-5.2 стала реальным вариантом, а не компромиссом.
Часто задаваемые вопросы
Чем GLM-5.2 лучше GLM-5.1?
Главное отличие — контекст вырос с 200K до 1M токенов и стал реально стабильным на длинных агентных траекториях. FrontierSWE вырос с 30.5% до 74.4% — это кардинальный скачок. SWE-bench Pro прибавил с 58.4% до 62.1%, Terminal-Bench 2.1 — с 63.5% до 81.0%. Введены режимы рассуждения High и Max.
Где взять GLM-5.2 без VPN из России?
Через AITUNNEL — OpenAI-совместимый прокси с оплатой в рублях. Базовый URL: api.aitunnel.ru/v1, модель: glm-5.2. Ввод 268.8 ₽/1M токенов, вывод 844.8 ₽/1M токенов. Минимальное пополнение 399 ₽.
Можно ли запустить GLM-5.2 локально?
Да, веса на HuggingFace (zai-org/GLM-5.2) под MIT-лицензией. Поддерживаются vLLM, SGLang, transformers, xLLM, ktransformers. Для fp8-инференса нужно несколько GPU H100 80GB — это серверное железо. Community-квантизации для меньшего VRAM появятся в течение месяца после публикации весов.
Где GLM-5.2 проигрывает закрытым моделям?
SWE-Marathon: 13.0 против 26.0 у Opus 4.8 — вдвое меньше на задачах уровня «написать компилятор». Tool-Decathlon: 48.2 против 59.9 у Opus 4.8. DeepSWE: 46.2 против 70.0 у GPT-5.5. NL2Repo: 48.9 против 69.7 у Opus 4.8.
Какие инструменты поддерживают GLM-5.2?
Claude Code (model: "GLM-5.2" или "GLM-5.2[1m]" для 1M контекста), OpenCode, ZCode. Через API работают function calling, streaming, JSON Schema, MCP. Совместим с OpenAI SDK через смену базового URL.
Доступ к этому провайдеру через AITUNNEL
Все модели провайдера доступны через единый API. Работает из России без VPN, оплата в рублях.
За последние два года рынок языковых моделей изменился до неузнаваемости. Если в 2023 году вопрос сводился к «ChatGPT или что-то другое», то сегодня выбор модел…
Рынок языковых моделей в 2025–2026 году развивается с такой скоростью, что даже опытные разработчики успевают за новинками с трудом. Если год назад выбор сводил…
Если попросить любого разработчика назвать первую AI-компанию, которая приходит на ум, 9 из 10 скажут OpenAI. Это не случайно: именно ChatGPT в ноябре 2022 года…