Обзор нового флагмана GLM-5.1 от Z.ai для агентского кодинга — тесты использования, полная таблица бенчмарков и то, где модель действительно берёт своё
GLM-5 мы разбирали в прошлом году, тогда это была крепкая рабочая модель для агентских задач. Но с тех пор пространство флагманов сильно изменилось, и вот новая — GLM-5.1. Z.ai называет его «следующим поколением для агентного программирования», и на этот раз за этим стоят конкретные числа.
Главное, что отличает GLM-5.1 от предшественника — не скорость и не размер контекста, а то, что модель умеет оставаться продуктивной на длинных дистанциях. Там, где другие модели сбавляли темп и начинали ходить по кругу, GLM-5.1 продолжает работать. Разбивает задачу на части, запускает эксперименты, читает результаты, меняет стратегию. И чем дольше — тем лучше итог.
Почему предыдущие модели зависали на длинных задачах
Большинство моделей работают по одной схеме — дай им больше времени, станет лучше, но только до какого-то предела. Дальше они просто повторяют одни и те же действия, не находя ничего нового.
GLM-5.1 ведёт себя по-другому. Вместо того чтобы застрять на одном подходе, модель разбирает задачу на части, пробует разные варианты, смотрит что получилось и меняет план. И так до тех пор, пока есть куда двигаться.
Чтобы не быть голословными, проверили это на трёх разных задачах. Первая — с понятной числовой оценкой, вторая — уже сложнее, а третья вообще без метрики: качество результата модель оценивала сама. Специально подобрали разные форматы, чтобы посмотреть, где именно преимущество теряется.
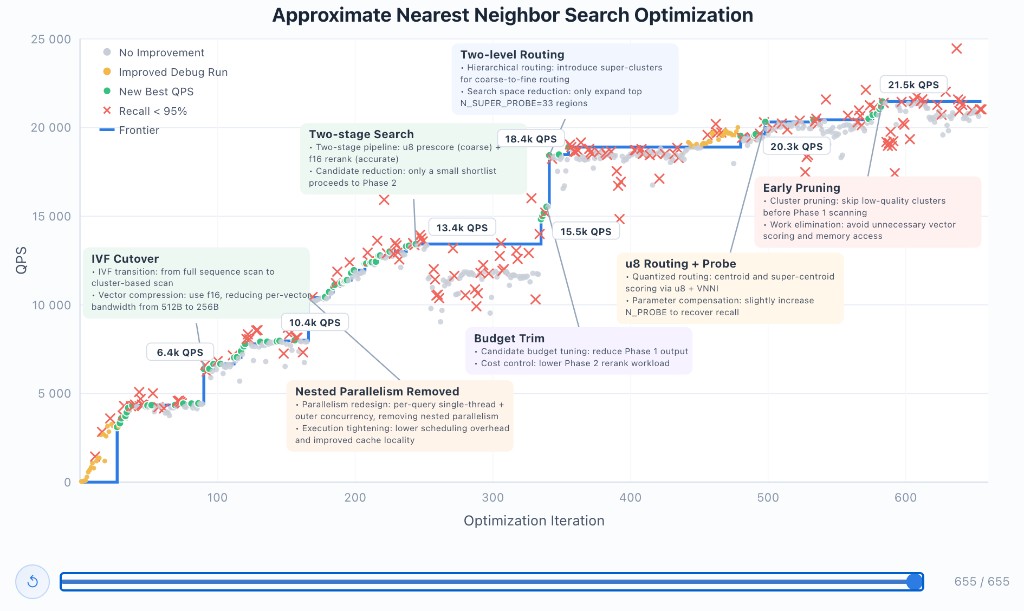
Тест №1. Оптимизация векторной базы данных
VectorDBBench — open-source задача, где нужно построить быструю базу данных для поиска по похожим векторам. Модель получает Rust-код с заготовками и 50 ходов, чтобы компилировать, тестировать и профилировать. Итоговая оценка — сколько запросов в секунду (QPS) база обработает на датасете SIFT-1M при точности не ниже 95%. До GLM-5.1 в рамках этого лимита лучший результат был 3 547 QPS — его поставил Claude Opus 4.6.
Мы решили убрать ограничение в 50 ходов и запустить модель в петлю: каждый раз GLM-5.1 делает сколько угодно вызовов инструментов, а потом сам решает — засабмитить текущую версию или продолжать работать. После 600 итераций и больше 6 000 tool-вызовов результат вырос до 21 500 QPS. Это примерно в 6 раз больше, чем лучший результат в стандартном 50-ходовом режиме.
Но интереснее не сама цифра, а то, как модель к ней шла. График роста QPS выглядит как лесенка — долгие периоды, когда модель доводит одну и ту же идею, а потом резкий скачок, когда она меняет подход целиком. Примерно на 90-й итерации она перешла с полного перебора на IVF-кластеризацию и сжатие векторов до f16 — QPS подскочил до 6 400. На 240-й добавила двухэтапный пайплайн с грубым отбором через u8 и точным реранкингом — уже 13 400 QPS. Таких больших переходов за весь прогон было шесть, и каждый раз модель принимала решение сама, анализируя собственные логи.
Рисунок 1. Траектория оптимизации VectorDBBench: рост QPS по итерациям с ключевыми переключениями стратегии.
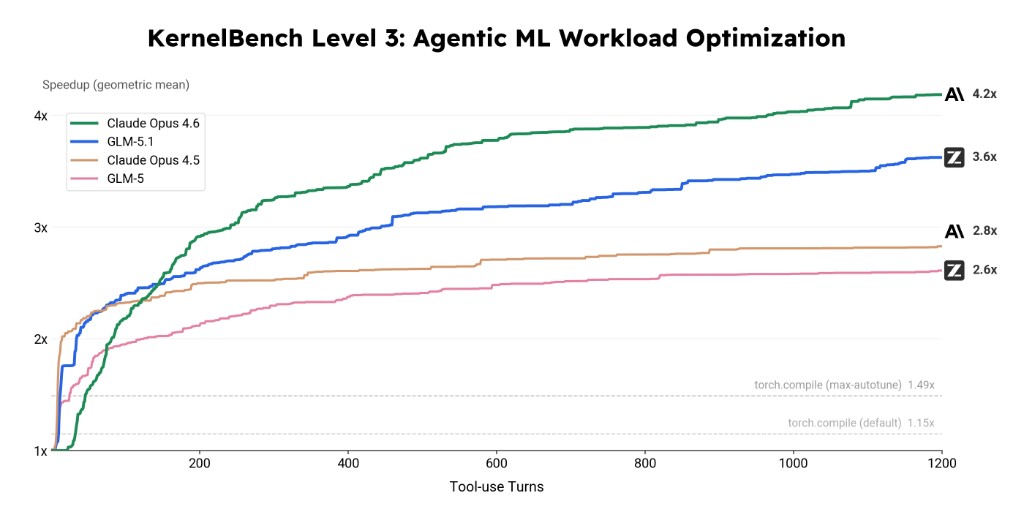
Тест №2. Оптимизация GPU-ядер за 1 000+ ходов
KernelBench Level 3 — задача на переписывание PyTorch-кода в более быстрое GPU-ядро, которое даёт те же результаты. Третий уровень — самый сложный: нужно оптимизировать целые архитектуры вроде MobileNet, VGG, MiniGPT и Mamba, всего 50 задач. Чтобы было с чем сравнивать: стандартный torch.compile даёт ускорение в 1.15×, с агрессивными настройками — 1.49×.
Здесь GLM-5.1 уже не первый. Claude Opus 4.6 добрался до 4.2× и к концу трека всё ещё продолжал расти. GLM-5.1 показал 3.6× — заметно лучше, чем GLM-5, который останавливался гораздо раньше. Claude Opus 4.5 тоже раньше терял темп по сравнению с GLM-5.1. Но разрыв с Opus 4.6 — около 0.6× — это не погрешность, это реальное отставание.
Рисунок 2. KernelBench Level 3: среднее ускорение по числу tool-use ходов, сравнение GLM-5.1 с Opus и предыдущей версией GLM.
Тест №3. Linux-десктоп в браузере за 8 часов
Этот тест принципиально другой — никакой числовой оценки нет вообще. Задача звучит просто: сделай Linux-подобный рабочий стол как веб-приложение. Без готового кода, без макетов, без подсказок по ходу. Один промпт — и погнали.
Большинство моделей в такой ситуации делают одно и то же — рисуют тулбар, добавляют пару заглушек-окон и на этом останавливаются. Формально задача выполнена. Спросить себя «а что тут ещё можно доделать» они не умеют.
GLM-5.1 завернули в петлю: после каждого раунда модель смотрит на то, что уже есть, сама решает, чего не хватает — недоделанные фичи, некрасивый вид, что-то сломанное — и идёт дальше. Этот цикл крутился 8 часов.
Разница видна невооружённым глазом. В начале — тот же стандартный тулбар и простое окно. Но потом постепенно появляется всё больше: файловый менеджер, терминал, текстовый редактор, системный монитор, калькулятор, игры. Причём каждая новая штука не просто добавляется как попало — она встраивается в общий интерфейс. Через 8 часов получилась полноценная среда рабочего стола, которая работает прямо в браузере.
GLM-5.1 среди флагманов — полная таблица бенчмарков
Ниже — сводная таблица по всем основным бенчмаркам. Синим выделены результаты GLM-5.1, жирным — лучший результат в каждой строке.
Бенчмарк
GLM-5.1
GLM-5
Qwen3.6+
DeepSeek V3.2
Kimi K2.5
Claude Opus 4.6
Gemini 3.1 Pro
GPT-5.4
Рассуждение
HLE
31.0
30.5
28.8
25.1
31.5
36.7
45.0
39.8
AIME 2026
95.3
95.4
95.1
95.1
94.5
95.6
98.2
98.7
HMMT Nov. 2025
94.0
96.9
94.6
90.2
91.1
96.3
94.8
95.8
HMMT Feb. 2026
82.6
82.8
87.8
79.9
81.3
84.3
87.3
91.8
IMOAnswerBench
83.8
82.5
83.8
78.3
81.8
75.3
81.0
91.4
GPQA-Diamond
86.2
86.0
90.4
82.4
87.6
91.3
94.3
92.0
Кодирование
SWE-Bench Pro
58.4
55.1
56.6
—
53.8
57.3
54.2
57.7
NL2Repo
42.7
35.9
37.9
—
32.0
49.8
33.4
41.3
Terminal-Bench 2.0
63.5
56.2
61.6
39.3
50.8
65.4
68.5
—
CyberGym
68.7
48.3
—
17.3
41.3
66.6
38.8
66.3
Агентные задачи
BrowseComp
68.0
62.0
—
51.4
60.6
—
—
—
τ³-Bench
70.6
69.2
70.7
69.2
66.0
72.4
67.1
72.9
MCP-Atlas
71.8
69.2
74.1
62.2
63.8
73.8
69.2
67.2
Tool-Decathlon
40.7
38.0
39.8
35.2
27.8
47.2
48.8
54.6
Таблица 1. Сводные результаты бенчмарков из релиза GLM-5.1. Синим выделены значения GLM-5.1, жирным — лучший результат в строке.
На кодировании — SWE-Bench Pro, CyberGym и BrowseComp — GLM-5.1 лидирует или в первой тройке. На рассуждении картина другая: HLE (Humanity's Last Exam) — 31.0, тогда как Gemini 3.1 Pro набирает 45.0, Claude Opus 4.6 — 36.7. На математических задачах (AIME, HMMT) GLM-5.1 держится в группе лидеров, но не первый. Сильная сторона модели — именно агентное кодирование, а не общий интеллект.
Открытые веса, MIT-лицензия и как запустить
Если нужен быстрый доступ к GLM-5.1 без лишних танцев с оплатой и настройками, проще всего подключаться через AITUNNEL. Это легальный посредник с оплатой в рублях и OpenAI-совместимым API — удобно, если вы уже используете привычные SDK и не хотите переделывать интеграцию.
Схема простая. Регистрируетесь на AITUNNEL, пополняете баланс, получаете API-ключ и в своём коде меняете только базовый адрес на https://api.aitunnel.ru/v1/. Дальше выбираете модель "GLM-5.1" — и можно работать как с обычным OpenAI-style endpoint (стриминг, инструменты и остальная механика остаются на месте).
Если же вам важен локальный запуск и контроль инфраструктуры, у GLM-5.1 есть открытые веса под MIT-лицензией. Их можно скачать с HuggingFace или ModelScope и поднять через vLLM или SGLang. Официальные эндпойнты Z.ai тоже остаются в доступе — api.z.ai и BigModel.cn.
Что в итоге
58.4% на SWE-Bench Pro — хороший результат, но не главное. Главное то, что GLM-5.1 не теряет продуктивность на длинных задачах. В агентных сценариях это важно.
VectorDB с 600 итерациями и реальным замером QPS, GPU-ядра с конкретным ускорением, Linux-десктоп вообще без метрики — совершенно разные форматы. И в каждом GLM-5.1 держал курс, не теряя продуктивность к концу.
Слабые места тоже есть. На KernelBench Opus 4.6 пока быстрее. На задачах чистого рассуждения и математике — HLE, HMMT — GLM-5.1 отстаёт от лучших моделей OpenAI и Google. Но если задача про кодирование, генерацию репозиториев или кибербезопасность — это рабочая альтернатива. С открытыми весами и MIT-лицензией, что само по себе уже аргумент.
Флагманская модель Z.ai для агентного программирования нового поколения. Значительно превосходит GLM-5 в кодировании и работе на длинных горизонтах задач. Достигает SOTA на SWE-Bench Pro (58.4%), лидирует на NL2Repo (42.7%) и Terminal-Bench 2.0. Ключевое отличие — способность сохранять продуктивность на протяжении сотен итераций и тысяч tool-вызовов. Открытые веса, MIT-лицензия.
Ключевые преимущества
58.4% на SWE-Bench Pro — лучший результат среди сравниваемых моделей
42.7% на NL2Repo — первое место по генерации репозиториев
68.7% на CyberGym — впереди Claude Opus 4.6 и GPT-5.4
68.0% на BrowseComp — лучший в группе
Открытые веса под MIT-лицензией на HuggingFace и ModelScope
GLM-5.1 — убедительный шаг Z.ai в сторону длинных агентных горизонтов. Лучший результат на SWE-Bench Pro (58.4%), уверенное лидерство на CyberGym и BrowseComp, и — что важнее цифр — реальная демонстрация того, что модель не теряет продуктивность на длинных дистанциях. Открытые веса под MIT-лицензией с поддержкой vLLM и SGLang делают её реальным вариантом для on-premise production. Если ваши задачи — агентное кодирование, оптимизация, генерация репозиториев или кибербезопасность — GLM-5.1 заслуживает серьёзного внимания.
Часто задаваемые вопросы
Чем GLM-5.1 лучше GLM-5?
GLM-5.1 существенно сильнее в кодировании (58.4% vs 55.1% на SWE-Bench Pro) и особенно на длинных горизонтах задач. GLM-5 выходил на плато после 50–100 итераций; GLM-5.1 продолжает находить улучшения через сотни итераций. На NL2Repo — 42.7% vs 35.9% у GLM-5.
Можно ли запустить GLM-5.1 локально?
Да. Веса опубликованы на HuggingFace (zai-org/GLM-5.1) и ModelScope (ZhipuAI/GLM-5.1) под MIT-лицензией. Для развёртывания поддерживаются vLLM и SGLang. Инструкции — в официальном GitHub-репозитории Z.ai.
С какими инструментами совместим GLM-5.1?
GLM-5.1 совместим с Claude Code — достаточно указать model: "GLM-5.1" в настройках. Также работает с OpenCode, Kilo Code, Roo Code, Cline, Droid. Через API доступен на api.z.ai и BigModel.cn.
Как GLM-5.1 ведёт себя на бенчмарках по рассуждению?
На математике конкурентоспособен: AIME 2026 — 95.3%, HMMT Nov. 2025 — 94.0%, GPQA-Diamond — 86.2%. На HLE (Humanity's Last Exam) — 31.0, что уступает GPT-5.4 (39.8) и Claude Opus 4.6 (36.7). Сильная сторона GLM-5.1 — кодирование и агентные задачи.
Доступен ли GLM-5.1 без VPN из России?
API доступен через api.z.ai. Для удобной работы без дополнительных настроек можно использовать прокси-сервис AITUNNEL с OpenAI-совместимым endpoint и оплатой в рублях.
Доступ к этому провайдеру через AITUNNEL
Все модели провайдера доступны через единый API. Работает из России без VPN, оплата в рублях.
За последние два года рынок языковых моделей изменился до неузнаваемости. Если в 2023 году вопрос сводился к «ChatGPT или что-то другое», то сегодня выбор модел…
Рынок языковых моделей в 2025–2026 году развивается с такой скоростью, что даже опытные разработчики успевают за новинками с трудом. Если год назад выбор сводил…
Если попросить любого разработчика назвать первую AI-компанию, которая приходит на ум, 9 из 10 скажут OpenAI. Это не случайно: именно ChatGPT в ноябре 2022 года…